WHAT IS A RUBY GEM?
A gem is essentially a Ruby plugin. RubyGems is a package manager for the Ruby programming language that provides a standard format for distributing Ruby programs and libraries, a tool designed to easily manage the installation of gems, and a server for distributing them.
WHY USE GEM?
(Interesting question. Let’s see why.)
Before we get into the “how” of creating a gem, let’s first consider why you might want to do so.
One of the most obvious reasons relates to code reuse.
If you find yourself implementing the same feature over and over again across projects, there’s a good chance that you’ve found the need for a gem.
Additionally, releasing a gem as open-source provides others the opportunity to contribute by adding features, addressing issues that you might have overlooked, and generally making your gem provide an all-around better experience for its users.
HOW DO YOU BUILD A GEM?
To help us create the gem, we’ll use the popular bundler
bundler gem <gem_name>
Bundler is primarily designed to help you manage a project’s dependencies.
If you’ve not used it before, then don’t worry because we’ll be taking advantage of a lesser known feature anyway, which is its ability to generate a gem boilerplate. (
It also provides some other tools that will help us manage our gem’s packaging).
Let’s begin by installing bundler:
gem install bundler
Once Bundler is installed, we can use it to create our gem.
To begin to create a gem using Bundler named megam_api, use the bundle gem command like this:
bundle gem megam_api
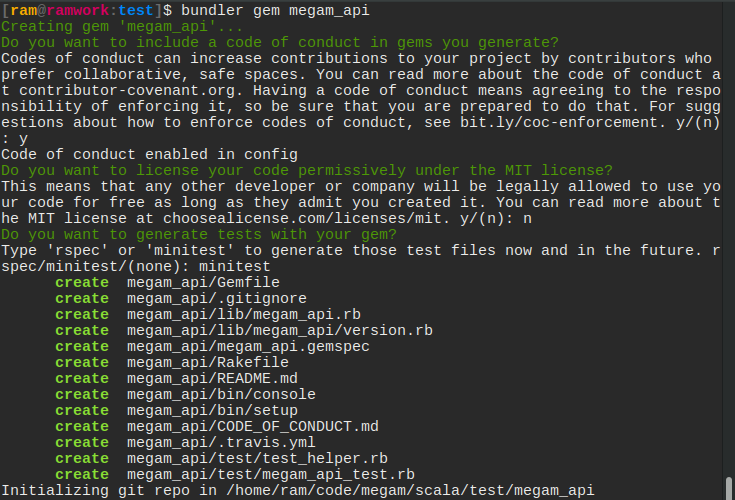
We call our gem megam_api because this gem is going to do a couple of things around Megam cloud platfom such as magically launch an app in cloud or “suck in cloud!”.
This command creates a scaffold directory for our new gem.
The files generated are:
Gemfile: Used to manage gem dependencies for our library’s development. This file contains a gemspec line meaning that Bundler will include dependencies specified in megam_api.gemspec too.
Rakefile: Requires Bundler and adds the build, install and release Rake tasks by way of calling Bundler::GemHelper.install_tasks. The build task will build the current version of the gem and store it under the pkg folder, the install task will build and install the gem to our system (just like it would do if we gem install’d it) and release will push the gem to Rubygems for consumption by the public.
.gitignore: (only if we have Git). This ignores anything in the pkg directory (generally files put there by rake build), anything with a .gem extension and the .bundle directory.
megam_api.gemspec: The Gem Specification file. This is where we provide information for Rubygems’ consumption such as the name, description and homepage of our gem. This is also where we specify the dependencies our gem needs to run.
lib/megam_api.rb: The main file to define our gem’s code. This is the file that will be required by Bundler (or any similarly smart system) when our gem is loaded. This file defines a module which we can use as a namespace for all our gem’s code. It’s best practice to put our code in…
lib/megam: here. This folder should contain all the code (classes, etc.) for our gem. The lib/megam_apie.rb file is there for setting up our gem’s environment, whilst all the parts of it go in this folder. If our gem has multiple uses, separating this out so that people can require one class/file at a time can be really helpful.
lib/megam/api/version.rb: Defines a Megam api module and in it, a VERSION constant. This file is loaded by the megam_api.gemspec to specify a version for the gem specification. When we release a new version of the gem we will increment a part of this version number to indicate to Rubygems that we’re releasing a new version.
There’s our base and our layout, now get developing!
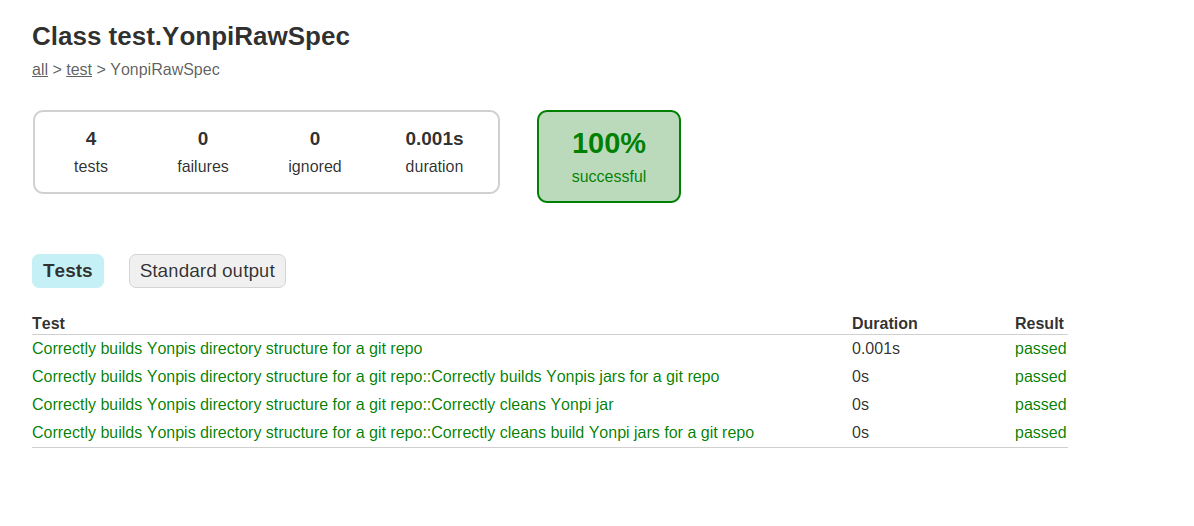
TESTING YOUR GEM:
We’re going to use minitest to test our gem.
-We write tests to ensure that everything goes according to plan and to prevent future-us from building a time machine to come back and kick our asses.
-To get started with writing our tests, we’ll create a test directory at the root of gem by using the command:
mkdir test
-Next, we’ll specify in our megam_api.gemspec file that minitest is a development dependency by adding this line inside theGem::Specification block:
spec.add_development_dependency "minitest", "~> 5.8"
-Because we have the gemspec method call in our Gemfile, bundler will automatically add this gem to a group called “development” which then we can reference any time we want to load these gems with the following line:
Bundler.require(:default, :development)`
-The benefit of putting this dependency specification inside of megam_api.gemspec rather than the Gemfile is that anybody who runs
gem install megam_api --dev
will get these development dependencies installed too.
This command is used for when people wish to test a gem without having to fork it or clone it from GitHub.
-When we run bundle install, minitest will be installed for this library and any other library we use with bundler, but not for the system. This is an important distinction to make: any gem installed by Bundler will not muck about with gems installed by gem install. It is effectively a sandboxed environment.
-By running bundle install, bundler will generate the extremely important Gemfile.lock file. This file is responsible for ensuring that every system this library is developed on has the exact same gems so it should always be checked into version control.Additionally in the bundle install output, we will see this line:
Using megam_api (0.99) from source at /path/to/megam_api`
Bundler detects our gem, loads the gemspec and bundles our gem just like every other gem.
We can write our first test with this framework now in place.
For testing, create a new test file for every api (accounts to startwith) we want to test at the root of the test directory.
When we run ruby test_accounts.rb
require File.expand_path("#{File.dirname(__FILE__)}/test_helper")
class TestAccounts < MiniTest::Unit::TestCase
$admin = "admin-tom"
$normal = "normal-tom"
$tom_email = "tom@gomegam.com"
$bob_email = "bob@gomegam.com"
def test_get_accounts_good
response =megams.get_accounts(sandbox_email)
response.body.to_s
assert_equal(200, response.status)
end
def test_post_accounts_good
tmp_hash = {
"id" => "000099090909000",
"first_name" => "Darth",
"last_name" => "Vader",
"email" => "coolvader@iamswag.com",
"phone" => "19090909090",
"api_key" => "IamAtlas{74}NobdyCanSedfefdeME#07",
"authority" => "admin",
"password" => "",
"password_reset_key" => "",
"password_reset_sent_at" => "",
"created_at" => "2014-10-29 13:24:06 +0000"
}
response =megams.post_accounts(tmp_hash)
response.body.to_s
assert_equal(201, response.status)
end
end
To load this file, we’ll need to add a require line to lib/megam_api.rb for it:
require ‘megam_api/api/accounts’
When we run our specs with ruby test_accounts.rb this test will pass:
2 example, 0 failures
Great success! If we’re using Git (or any other source control system), this is a great checkpoint to commit our code. Always remember to commit often!
It’s all well and dandy that we can write our own code.
PUBLISHING TO RUBYGEMS.ORG
The simplest way to distribute a gem for public consumption is to use RubyGems.org.
Gems that are published to RubyGems.org can be installed via the gem install command or through the use of tools such as Isolate or Bundler.
Create an account with rubygems.org
Register at [rubygems.org](https://rubygems.
Create a credentials file with the api_key
ram@ramwork:.gem]$ pwd
/home/ram/.gem
[ram@ramwork:.gem]$ ls
credentials ruby/ specs/
[ram@ramwork:.gem]$ cat credentials
---
:rubygems_api_key: 8690909090909090909090afdasfasdf90
Build a gem
cd megam_api
gem build megam_api.gemspec
Successfully built RubyGem
Name: megam_api
Version: 0.90
File: megam_api-0.90.gem
Push your gem to rubygems.org
gem push megam_api-0.99.gem
Voila
You are done. Go ahead and hack your own gem.