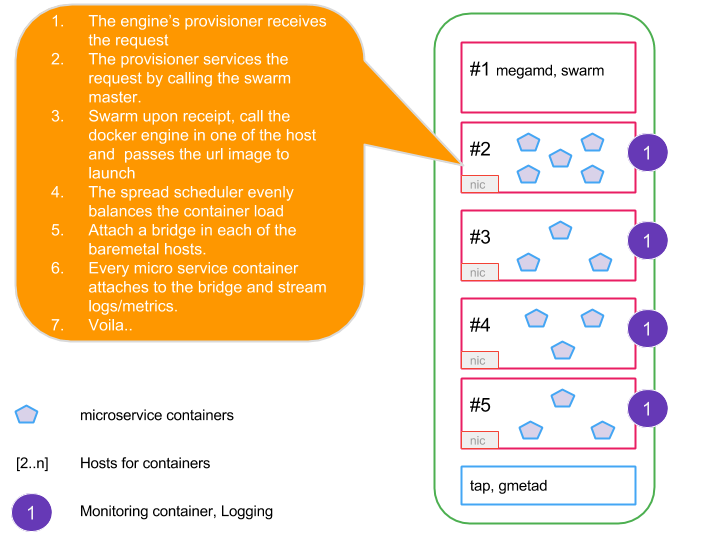
In Part1 we looked at how does the general RESTful API design for the input request look like.
We will use functional programming design technique - scalaz library and apply it to the design we have so far.
Scalaz
scalaz is an extension of the core library for functional programming.
Why functional ?
We can defer the computation until we need to actually do it.
Break programs in to partitioned computations
Just play with plain old data structures instead of fancy polymorphism types like AbstractBufferedToddlerReadyPlaySchool.
We will not cover scalaz here, however you can refer a tutorial to learn scalaz.
Some of the libraries that we will use are
- scalaz.Validation
- scalaz.effect.IO
- scalaz.EitherT._
- scalaz.NonEmptyList._
More precisely the following will be imported.
import scalaz._
import scalaz.Validation._
import Scalaz._
import scalaz.effect.IO
import scalaz.EitherT._
import scalaz.Validation
import scalaz.NonEmptyList._
import scalaz.Validation.FlatMap._
The first concept we will study is about, map. This isn’t a theory on monads, but talks about how we used it. so bear with me.
map
//A functor with one fuction.
def map[B](f: A => B) : M[B]
For example you can convert a List of Ints to String. Why would you want to do that ? Lets just say we feel cool :).
List[Int] -> List[String]
Lets change a list of Ints to Option[Int]
val listT = List(1,2,3)
listT.map(x => Some(x)) -> List[Option[Int]]
The next one we will use a lot is, flatMap.
flatMap
def flatMap[B](f: A => M[B]) : M[B]
Lets change a list of Ints to Option[Int]
val fruits = Seq("apple", "banana", "orange")
val ufruits = fruits.map(_.toUpperCase)
//lets first map the fruits to make them uppper case
:Seq[java.lang.String] = List(APPLE, BANANA, ORANGE)
ufruits.flatMap(_.toUpperCase)
//lets do a flatMap on the uppercased list
:Seq[Char] = List(A, P, P, L, E, B, A, N, A, N, A, O, R, A, N, G, E)
Validation
Many a times you will find try catch to be cumbersome in trapping errors. It becomes ugly where you start throwing down exceptions just to propogate and handle it.
Some times you need a value of the exception to proceed further or just halt there.
A better way would be to handle exceptions as a value. Here you can see that an CannotAuthenticateError is returned as below.
Validation.failure[Throwable, Option[String]](CannotAuthenticateError("""Invalid content in header. API server couldn't parse it""", "Request can't be funneled."))
Validation.success[Throwable, Option[String](Some("Hurray I am done"))
There are two type parameters in the above Throwable and Option[String]
We will use the term
Left to indicate the failure (Throwable) and
Right to indicate the success (Option[String])
During a failure, the Left is provided with the value of the failure.
During a success, the Right is provided with the success value.
ValidatioNel
ValidationNel is a convinient method to wrap a NonEmptyList to the list of results. It can be useful where you want to concatenate the results of chained computation.
For instance - hit the guys head with a nail 10 times and tell the results of it what happened each time.
Did the guy duck or get it ?
ValidationNel[Throwable, Option[Hit]]
There are convenient methods to change Validation to ValidationNel.
Where can you use ?
When you call your model to create something, you want to return all the results to the callee.
In the below code, we create an account and return the Left or Right to the callee.
Model results
The first step is that we send a json string to the model to store.
But first we need to validate it to a known schema AccountInput and see if it satisfies the same. If not we return an error MalformedBodyError
We wrap the schema extraction on Validation.fromTryCatch which results in Left or Right automatically.
So if we wanted to proceed with upon success of the schema validation we need to use a flatMap
So if we wanted to proceed with upon failure of the schema validation we need to use a leftMap
def create(input: String): ValidationNel[Throwable, Option[AccountResult]] = {
play.api.Logger.debug(("%-20s -->[%s]").format("models.Accounts", "create:Entry"))
play.api.Logger.debug(("%-20s -->[%s]").format("input json", input))
(Validation.fromTryCatch[models.AccountInput] {
parse(input).extract[AccountInput]
} leftMap { t: Throwable => new MalformedBodyError(input, t.getMessage)
}).toValidationNel.flatMap
Ignore the toValidationNel for now. We will get to it in a minute.
So you saw how easy its to trap failure/success in a simple scenario.
By using for comprehension imagine the power to chain computation which decides if it wants to proceed or exit out and inform the callee.
Sweet.
for {
m <- accountInput // verify the schema
bal <- //create an empty billing record
uid <- //get an unique id to store in riak
} yield {
//yield a success result
}
So you just understood how to chain computations to arrive at a result, as opposed to the imperative style of a humongous loads of classes.
We are going to proceed further and explore calling our model a bunch of times and keep storing success or failure.
toValidationNel is a helper method that lets you convert a Validation to ValidationNel
ValidationNel comes handy.
ValidationNel put to use
Let us take a scenario where in our case when an user clicks the button Marketplaces we want to talk to the gateway - REST API server

to display the Marketplaces screen

Yeah. Here is the code.
def findByName(marketPlacesNameList: Option[Stream[String]]): ValidationNel[Throwable, MarketPlaceResults] = {
(marketPlacesNameList map {
_.map { marketplacesName =>
InMemory[ValidationNel[Throwable, MarketPlaceResults]]({
cname: String => {
(riak.fetch(marketplacesName) leftMap { t: NonEmptyList[Throwable] =>
new ServiceUnavailableError(marketplacesName, (t.list.map(m => m.getMessage)).mkString("\n"))
}).toValidationNel.flatMap { xso: Option[GunnySack] =>
xso match {
case Some(xs) => { (Validation.fromTryCatchThrowable[models.MarketPlaceResult,Throwable] { parse(xs.value).extract[MarketPlaceResult]
} leftMap { t: Throwable =>
new ResourceItemNotFound(marketplacesName, t.getMessage)
}).toValidationNel.flatMap { j: MarketPlaceResult =>
Validation.success[Throwable, MarketPlaceResults](nels(j.some)).toValidationNel //screwy kishore, every element in a list ?
}
}
case None => Validation.failure[Throwable, MarketPlaceResults](new ResourceItemNotFound(marketplacesName, "")).toValidationNel
}
}
}
}).get(marketplacesName).eval(InMemoryCache[ValidationNel[Throwable, MarketPlaceResults]]())
}
} map {
_.foldRight((MarketPlaceResults.empty).successNel[Throwable])(_ +++ _)
}).head //return the folded element in the head.
}
Lets examine the code. What we are saying here is
I hand you a list of Option[marketplace names], call the db and get me a ValidationNel[Failure/Success result] for each of the list item
- The first step is to map on the marketplaceName and start unwrapping what is inside it.
- As the type is Option[Stream] we see a double map
- There is a State monad cache InMemory used here which basically caches read only information inmemory or memcache as configured. The design details of State Monad will be explained in another article.
- For every element marketplacesName see if it came out successful (leftMap), if not set ResourceItemNotFound for this result
- If the result is successsful, then validate its schema that was stored before and keep accumulating the result
Note: Here you see that the computation results are to be store in a list of ValidationNel’s List[ValidationNel]
- At the end hence we use fold using a Successful accumulator to get the head which contains the results.
Super cool. eh!…
###Usage of flatMap
When you receive the result as Validation, the subsequent computation needs to handle (Left) or (Right).
To do so, we use our friend flatMap
In the below code, we marshall a json to a Scala object called models.AccountInput
(Validation.fromTryCatch[models.AccountInput] {
parse(input).extract[AccountInput]
} leftMap { t: Throwable => new MalformedBodyError(input, t.getMessage)
}).toValidationNel.flatMap { m: AccountInput =>
The result of the marshalling can result in an exception or models.AccountInput object
If the results are successful then the flatMap will provide the AccountInput object as seen above.
###either[T, S] \/
Wait isn’t either \/ disjunction appear like Validation.
Note either \/ is isomorphic to Validation.
What the heck is isomorphism. ?
Isomorphism is a very general concept that derives from the Greek iso, meaning “equal,” and morphosis, meaning “to form” or “to shape.”
Lets take this example and illustrate how either[T,S] differs from Validation.
For instance - hit the guys head with a nail 10 times and tell the singular result of failure or success by aggregating everything.
- 1st hit [Sucess]
- 2nd hit [Failure]
- 3rd hit [Success]
Did the guy duck or get it considering even on hit is a failure ? Yes the answer to the above is [Failure]
Lets study by taking an example.
(for {
resp <- eitherT[IO, NonEmptyList[Throwable], Option[AccountResult]] { //disjunction Throwabel \/ Option with a Function IO.
(Accounts.findByEmail(freq.maybeEmail.get).disjunction).pure[IO]
}
found <- eitherT[IO, NonEmptyList[Throwable], Option[String]] {
val fres = resp.get
val calculatedHMAC = GoofyCrypto.calculateHMAC(fres.api_key, freq.mkSign)
if (calculatedHMAC === freq.clientAPIHmac.get) {
(("""Authorization successful for 'email:' HMAC matches:
|%-10s -> %s
|%-10s -> %s
|%-10s -> %s""".format("email", fres.email, "api_key", fres.api_key, "authority", fres.authority).stripMargin)
.some).right[NonEmptyList[Throwable]].pure[IO]
} else {
(nels((CannotAuthenticateError("""Authorization failure for 'email:' HMAC doesn't match: '%s'."""
.format(fres.email).stripMargin, "", UNAUTHORIZED))): NonEmptyList[Throwable]).left[Option[String]].pure[IO]
}
}
} yield found).run.map(_.validation).unsafePerformIO() }
In the above there are two computations resp, found that are wrapped in eitherT[IO, NonEmptyList[Throwable], Option[T]]
The first computation returns the results of Account.findByEmail and wraps it in pure[IO]
The second computation takes the success of the find and see if account is valid and can be authenticated.
At the end of the computation you will notice that we yield the found where we convert it to a Validation and tell scala to run the unsafe mode now.
I suppose we have given you an overall perspective of just 3 things in the scalaz world.
- map, flatMap
- Validation, ValidationNel
- eitherT
We had applied the same in how this was used in our awesome api server https://github.com/megamsys.
If you guys want to learn more then press a few likes here functional conf